Data Aggregation Module
Background
While OpenMRS serves as a platform for building a medical record system within a specific healthcare network, it also can provide very valuable data which, when analyzed, creates insight into the disease burden of a region and its population health. A large instance of OpenMRS contains an immense set of data that can significantly benefit individuals that are interested in analyzing it. Privacy is an important consideration with data aggregation as healthcare data contains a large amount of patients' personal information.
The results from the analysis of this anonymous data balances the needs of both the implementers of OpenMRS and the research community. A closer look at information involving disease burden and population health gives the implementers of OpenMRS a better perspective as to what new features may be needed or old features that need to be updated/improved by the developers. Likewise, the analysis will provide researchers with better knowledge of diseases in specific areas and the burden they place on different parts of that region.
Objective
The objective of the Data Aggregation Module is to aggregate anonymous data across multiple instances of OpenMRS through a REST-Like interface. The module utilizes Hibernate to execute the SQL statement needed to access the requested, anonymous data from the database. Currently, the module supports 2 queries: Tests Ordered and Disease Counts.
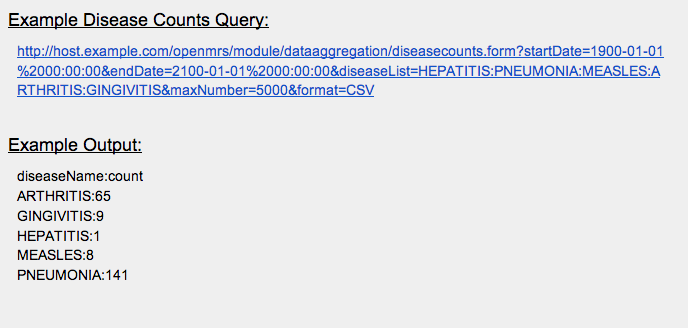
Disease Counts
The disease counts can be used to compile data on the disease burden of patients in the OpenMRS instance(s), customized based on specific diseases, cities, time period of diagnosis, and minimum/maximum number of cases.
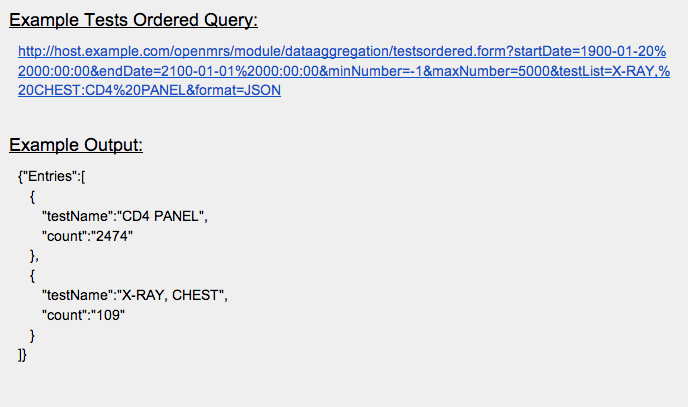
Tests Ordered
The Tests Ordered query gathers data from an OpenMRS instance that represents a total count of all tests ordered and can be customized based on specific tests, a set of certain locations, occurrence of tests during a time period, minimum/maximum number of cases, and output format.
What do these queries provide?
The data can be returned in 3 different file formats: JSON, XML, and CSV. These file formats help organize the data, allowing it to be graphed easily utilizing different data visualization tools like D3, R, or even a simple spreadsheet application like Excel.
When used with multiple instances of OpenMRS, this module can produce robust data to be graphed and help answer really interesting questions about population health.
The results themselves can be used to analyze different aspects of population health and disease burden, such as:
- Disease Burden of a selected OpenMRS instance or multiple instances
- Change in Disease Counts over time of a selected OpenMRS instance or multiple instances
- Disease Burden of specific Cities/Regions
- Change in Tests Ordered over time by location
- Change in Disease Burden over time in specific regions to measure growth and view possible outbreak
- Disease Burden shown by region
Participating Parties
The Data Aggregation Module is being developed as a result of a collaboration between Moravian College and Merck Pharmaceuticals. Students at Moravian College have been working on the development of the module throughout various courses and as independent research. Merck has provided the students with mentoring and support throughout the development.