Visit Notes Analysis Module
Abstract
This module is designed to recognize bio-medical entities that fall within one of the following three categories: Problem, Treatment, and Test. Problems can include diagnoses, symptoms, findings, etc. The implementer can indicate problems of interest. The module recognizes these entities in Visit Notes as they are being recorded by the clinician. After these entities have been identified, they are used to provide snapshot summaries of the information held within the larger text. This allows a practitioner to quickly summarize the content of the text and locate the information of interest.
The algorithm used can be 'trained' to perform the task by providing it with examples. With this in mind, we provide a companion web application to retrain the algorithm based on examples from an OpenMRS implementation. Training is not required to start using the module because we have already trained the algorithm, however, performance can be improved by showing the algorithm local examples.
Sample Screenshots
After loading the module the user would first browse to the patient dashboard:
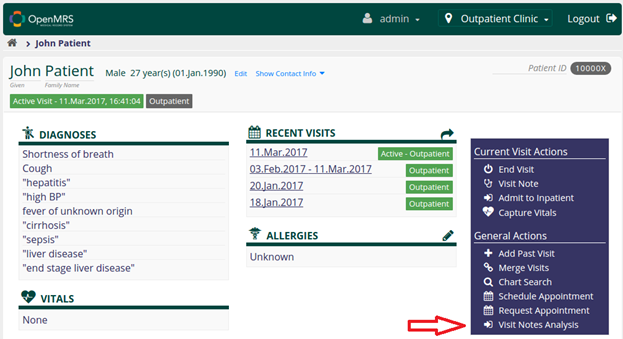
After selecting the Visit Notes Analysis action the user would see the following screen.
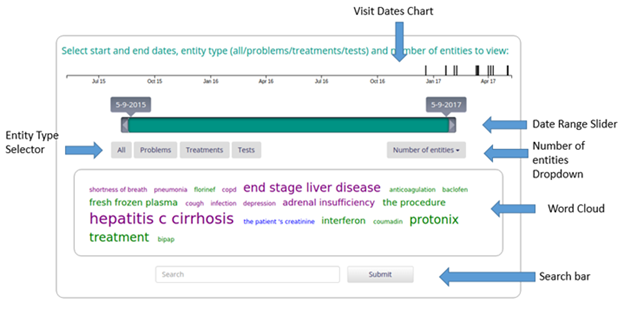
The word cloud shows a visualization of the most frequent entities that appear in the Visit Notes associated with the patient. The relative size of each entity corresponds to the relative frequency of the entity. An entity with a large font size appears more frequently than an entity with a smaller font size. The word cloud can be updated by changing the slider dates, selecting an entity type or number of entities. Upon adding entities of interest to the search bar and clicking 'Submit', the second page is displayed.
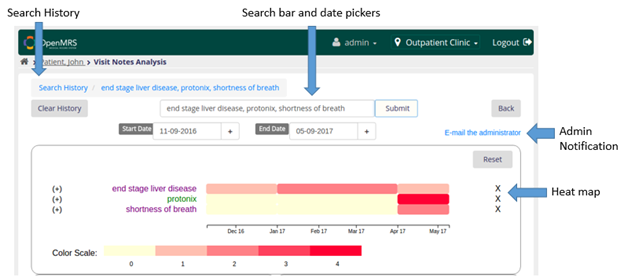
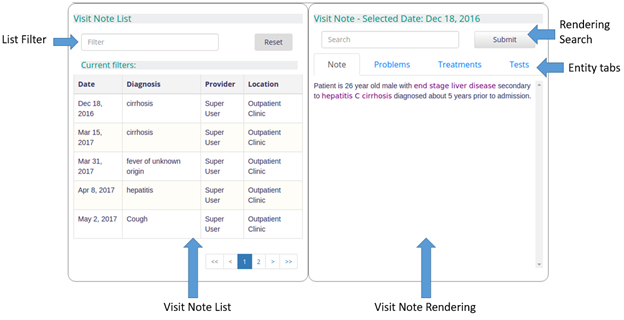
Please refer to the User's Guide for a complete description of this module.
Note, the analyzer will pick off entities, which include all concepts mentioned in the visit notes that are included in the concept dictionary. In addition, the analyzer will pick off entities found by application of natural language processing (NLP) along with named entity recognition (NER) algorithms.
Coupled with the analyzer is a training application that can be used to improve performance of the module based on any given local context where OpenMRS is being used.
For a more detailed description of the use of the module (by, e.g., clinicians), module installation, training based on a site’s visit notes, and description of the API that can be used by developers wishing to add NLP/NER facilities to their own module the reader is referred to the User’s Guide, Implementer’s Guide and Developer’s guide.
Limitations
During the development of this module, we performed evaluations of several NER algorithms in order to choose the best one to use here. During these evaluations it became clear that the current state of NER is not perfect. This module uses the BANNER NER system and our measurements showed that of the entities it finds, about 80% are correct. Also, it tends to find about 70% of the entities in the text. While this performance is good, it indicates that the results of this module should not be relied upon for perfect accuracy, and should be used as a tool to assist in analyzing Visit Notes.
Documentation
Downloads
Source Code
About
This module was developed by San Francisco State University for the OpenMRS community.
contact: kavya.katipally@gmail.com